
Understanding git
These days git is a very popular VCS (Version Control System), but many people find it difficult to use. I admit, it also took me many months to get comfortable with git. There are many git tutorials on the Web, but lots of them focus on specific git commands, which is not helping to get up to speed with using git. Using git effectively requires understanding it on the conceptual level. Specific commands to achieve particular goals can easily be looked up on Google, but you cannot find something if you don’t know what you are looking for.
If you are struggling with git, this post has a chance to help you.
Traditional VCSes
Let’s start with the basics of traditional VCSes, with which most people are familiar. Traditional VCSes, such as Subversion, Perforce or ClearCase are usually centralized and have a linear perception of the lifetime of a repository.

Fig.1: Conceptual view of a Subversion-style repository.
In a traditional VCS, there is a linear timeline of commits (check-ins, revisions), which are usually numbered with incrementing integers. It is clear which commit came after which one. The working copy, i.e. the local state of the repository, is always synced to a specific commit. Syncing it to a different commit usually requires transferring data over the network. In order to create a new commit, the working copy must be synced to the latest commit (revision) and the delta between the working copy and the latest revision is used to create a new commit.
It is important to note, that in most traditional VCSes, syncing is always associated with overwriting the working copy (the locally synced state).
Branches are not supported. Branches are usually implemented by creating subdirectories in the repository. To download a specific branch, a subtree of the repository is synced.
Tags are supported in some traditional VCSes and can usually be moved from one commit to another when required (e.g. when a wrong commit was tagged). Other VCSes don’t support tags and implement tags like branches, with subdirectories.
The concept of git
In git, things are much more complex:

Fig.2: Conceptual view of a git repository
The main difference between git and traditional VCSes is that in git, a new commit can be created relative to any existing commit in the history of the repository. Compare this to traditional VCSes, where a new commit can only be relative to the latest commit.
The result of this is that a git repository contains a tree of commits. On the above diagram (Fig.2), commits are the green circle nodes with the root being the initial commit and the leaves being reachable via tags and branches.
Each commit represents a particular state of the tree at the time it was created, just like in most traditional VCSes.
Even though each commit is relative to a preceding commit (except initial commit), there is no total order of commits. Because of this, commits cannot be numbered with incrementing integers, so instead they are numbered with randomly generated 40-bit SHA-1 hashes. Whenever a new change is committed, a new random hash is generated for it. Hash collisions are possible, but in practice improbable. Commits can often be referred to on the command line by the initial hexadecimal digits of their hash, e.g. 7 digits.
Note that the git nomenclature does not relate directly to the physical world and requires explanation. Understanding the nomenclature also greatly helps with using git. The git nomenclature is also different from traditional VCSes, many git operations have familiar names, but perform something completely different.
Working copy
The working copy is the local state of the repository. Another, familiar term for it is “local tree”. This is the set of files and directories on which the user is working.
Editing files on disk in the working copy can be performed freely, like e.g. in Subversion, without any specific locking or checking out. By the way, the “checkout” operation in git has a completely different meaning.
Synchronizing working copy with selected revision
The “git checkout” command synchronizes the state of the working copy to a particular commit, referenced by its hash or by branch name. So the “git checkout” command downloads the state of the repository at the specified commit. It also requires the tree to be unmodified beforehand.
HEAD
HEAD (a red arrow on the diagram in Fig.2) is a pointer to a branch or a commit. When HEAD points to a branch, it is said to be attached. When HEAD points to a specific commit (hash), it is said to be detached. Typically, HEAD points to the commit to which the tree was last synced.
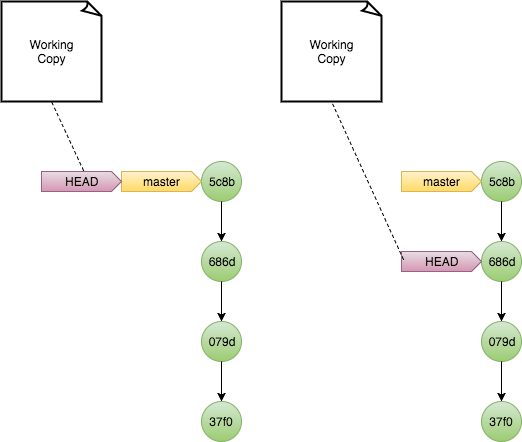
Fig.3: Attached HEAD vs. detached HEAD
Moreover, HEAD points to a commit (through a branch or directly) after which the next commit will be created. The creation of a next commit is a bit more complex than in a traditional VCS. Again, a new commit can be created relative to any existing commit in the tree.
When performing “git checkout”, which synchronizes the working copy with the specified commit, HEAD is automatically moved to that commit as well.
Being just a pointer, HEAD can also be moved to a different commit using the “git reset” command. By default this does not affect the working copy in any way. This is useful when you just committed two or more changes, but want to go back and commit them in a different way or in a different order.
Index
To create a new commit after files in the working copy have been locally modified, they first need to be added to the index (also a red arrow on the diagram in Fig.2). Initially the index is said to be empty. Files can be added to the index by using the “git add” command. This conceptually creates a temporary new commit, although this commit is not permanent or reachable via a hash. The commit is created as a delta between the working copy and the HEAD for the files being added.
Files in the working copy can be further modified and their delta will further be taken against the index. They can be added to the index again if needed, growing the potential new commit.
Alternatively, the “git reset” command can be used to remove files from the index. Any operation on the index creates a new temporary commit, but it does not actually create permanent commits. Remember that “git reset” is also used to move the HEAD pointer. “git reset” empties the index by default, but it also has an option to avoid affecting the index.
Commit
Finally, to create a new commit, the “git commit” command is used, which simply turns the index into a new commit. HEAD is then moved automatically to the new commit and the index is empty again. If HEAD is attached to a branch, the branch is moved to the new commit as well. This gives significance to attached or detached HEAD – for detached head no branch is moved when new commits are created. If there were any further local modifications to the working copy, which were not added to the index, these modifications are retained, because neither the “git add” nor the “git commit” operation affect the working copy in any way.
After a new change is committed, it cannot be modified or removed. There is a “git commit –amend” command, which is meant to modify the latest commit, it can add more files to a commit (via the index) or update commit message, but in practice it creates a new commit with a new hash (the amended commit has the same parent change as the original commit).
Detached HEAD
When new commits are added while HEAD is detached and then HEAD is moved to a different place, e.g. via “git checkout” or “git reset”, the commits added with detached HEAD become unreachable. They can still be reached if the user remembers their hashes or via “git reflog”, however once “git gc” is run (a.k.a. garbage collector), the unreachable commits are deleted completely.
Branches
Branches in git are simply named pointers to commits. They do not correspond to branches of the commit tree in a physical tree sense, pointers is all they are. A branch pointer can be freely moved to point to a different commit (selected via hash or other branch name) by using the “git branch” command.
In the example in Fig.2, the “develop” branch points to a leaf commit and potentially contains unstable changes, and the “master” branch points to an older commit, which is meant to be stable. Eventually the “master” branch pointer can be moved with “git branch -f” command to a newer, stable commit, or to where “develop” points to.
New branch pointers can be created with the “git branch” command and also with the “git checkout -b” command, which automatically attaches HEAD to the new branch. The new branch pointer will then be moved together with HEAD when new commits are created.
Tags
Tags in git are named commit pointers as well, just like branches and HEAD. See the blue pointer in Fig.2. Tags can also be moved, although git servers may restrict the movement of tags.
Distributed nature
Because commits are organized into a tree hierarchy, it is easy to use git repositories in a decentralized, collaborative way.
The “git clone” command creates a local copy of the repository. Typically this creates a copy of the entire repository locally, which becomes a new, local repository and references the remote repository.
The remote repository is by default called “origin” (it’s possible to have local shorthand names for remote repositories).
There can be multiple remote repositories registered and the user can pull (download) the state of selected repositories or push (upload) their changes to selected remote repositories. Both pulling and pushing can be done either for specified branches or for the entire repository.
Offline development
As mentioned above, the user typically has a copy of the whole repository locally, or of relevant branches. Therefore no network access is required to perform work on the repository. The user can commit multiple changes locally and sync the working copy to other commits or branches at will without performing any network access. Network access is only required to pull or push changes, i.e. to share with other users or for backup purposes.
Stash
Stash is a very useful feature which allows saving the current uncommitted modifications to the working copy using “git stash” command. This is useful e.g. when switching temporarily to a different branch or when downloading changes from a remote repository, without having to create a new dedicated commit. The work can later be resumed after restoring the saved modifications with “git stash pop”.
Summary
The key to using git effectively is understanding:
- The tree-like hierarchy of commits,
- The fact that “branches” and “tags” are simply pointers to commits,
- The purpose of HEAD and
- The fact that “branches” and HEAD can be freely moved around the tree.
The user interface of the command line git client is complicated and difficult to use due to unusual nomenclature and abundance of switches, which modify the commands in non-obvious ways. However, commands to perform concrete tasks can easily be looked up on Google. Check out this blog in the future for a git cheat sheet!
The great benefits of git are its reliability, robustness with regards to humongous repositories, multitude of tools supporting it and variety of services like GitHub.
See also: git log command variant, which makes it easier to view your current position in the tree.

Great article, Chris. ( I need to read through this more carefully, when I get a chance. )
I used to use RCS, and then CVS … ( back in Unix … ) Would those be considered ” Traditional “, or, pre-Traditional ? ( just kidding ). Thanks.
Thanks Larry, I hope it’s helpful. CVS etc. is “traditional” with its single/linear timeline of changelists (separately for every file). “Traditional” is probably not the best adjective here, after all git has become a classic already!
Great perspective. ( Oh, and I recalled ” SCCS ” too … that used to be a thing. ) I seem to recall that RCS came from IBM, or something to that effect. Anyway, this is a neat article.
Or maybe I’m thinking of ” RDB ” … probably both, from IBM. I had been chatting with an older engineer, from IBM, a couple of decades ago when we were at a park, at night ( it was a stargazing club meeting, just went for fun ) and I think he said that he had worked on the original RCS.
For some time, when tech companies would spend lots of money for a fully supported, highly integrated system, places I worked at were using things such as ClearCase and DesignSync. Now, with Git (and Perforce) there are newer ( maybe a little cheaper ) options.