
Archive
Understanding git
These days git is a very popular VCS (Version Control System), but many people find it difficult to use. I admit, it also took me many months to get comfortable with git. There are many git tutorials on the Web, but lots of them focus on specific git commands, which is not helping to get up to speed with using git. Using git effectively requires understanding it on the conceptual level. Specific commands to achieve particular goals can easily be looked up on Google, but you cannot find something if you don’t know what you are looking for.
If you are struggling with git, this post has a chance to help you.
Traditional VCSes
Let’s start with the basics of traditional VCSes, with which most people are familiar. Traditional VCSes, such as Subversion, Perforce or ClearCase are usually centralized and have a linear perception of the lifetime of a repository.

Fig.1: Conceptual view of a Subversion-style repository.
In a traditional VCS, there is a linear timeline of commits (check-ins, revisions), which are usually numbered with incrementing integers. It is clear which commit came after which one. The working copy, i.e. the local state of the repository, is always synced to a specific commit. Syncing it to a different commit usually requires transferring data over the network. In order to create a new commit, the working copy must be synced to the latest commit (revision) and the delta between the working copy and the latest revision is used to create a new commit.
It is important to note, that in most traditional VCSes, syncing is always associated with overwriting the working copy (the locally synced state).
Branches are not supported. Branches are usually implemented by creating subdirectories in the repository. To download a specific branch, a subtree of the repository is synced.
Tags are supported in some traditional VCSes and can usually be moved from one commit to another when required (e.g. when a wrong commit was tagged). Other VCSes don’t support tags and implement tags like branches, with subdirectories.
The concept of git
In git, things are much more complex:

Fig.2: Conceptual view of a git repository
The main difference between git and traditional VCSes is that in git, a new commit can be created relative to any existing commit in the history of the repository. Compare this to traditional VCSes, where a new commit can only be relative to the latest commit.
The result of this is that a git repository contains a tree of commits. On the above diagram (Fig.2), commits are the green circle nodes with the root being the initial commit and the leaves being reachable via tags and branches.
Each commit represents a particular state of the tree at the time it was created, just like in most traditional VCSes.
Even though each commit is relative to a preceding commit (except initial commit), there is no total order of commits. Because of this, commits cannot be numbered with incrementing integers, so instead they are numbered with randomly generated 40-bit SHA-1 hashes. Whenever a new change is committed, a new random hash is generated for it. Hash collisions are possible, but in practice improbable. Commits can often be referred to on the command line by the initial hexadecimal digits of their hash, e.g. 7 digits.
Note that the git nomenclature does not relate directly to the physical world and requires explanation. Understanding the nomenclature also greatly helps with using git. The git nomenclature is also different from traditional VCSes, many git operations have familiar names, but perform something completely different.
Working copy
The working copy is the local state of the repository. Another, familiar term for it is “local tree”. This is the set of files and directories on which the user is working.
Editing files on disk in the working copy can be performed freely, like e.g. in Subversion, without any specific locking or checking out. By the way, the “checkout” operation in git has a completely different meaning.
Synchronizing working copy with selected revision
The “git checkout” command synchronizes the state of the working copy to a particular commit, referenced by its hash or by branch name. So the “git checkout” command downloads the state of the repository at the specified commit. It also requires the tree to be unmodified beforehand.
HEAD
HEAD (a red arrow on the diagram in Fig.2) is a pointer to a branch or a commit. When HEAD points to a branch, it is said to be attached. When HEAD points to a specific commit (hash), it is said to be detached. Typically, HEAD points to the commit to which the tree was last synced.
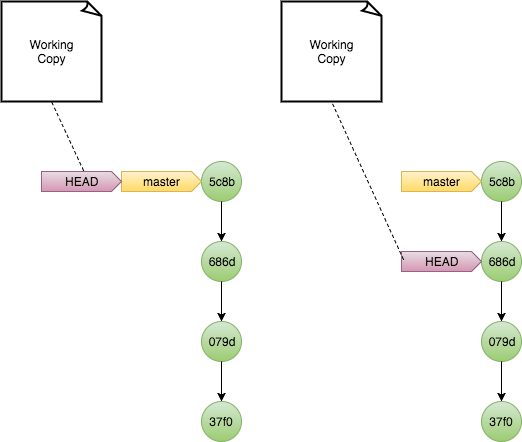
Fig.3: Attached HEAD vs. detached HEAD
Moreover, HEAD points to a commit (through a branch or directly) after which the next commit will be created. The creation of a next commit is a bit more complex than in a traditional VCS. Again, a new commit can be created relative to any existing commit in the tree.
When performing “git checkout”, which synchronizes the working copy with the specified commit, HEAD is automatically moved to that commit as well.
Being just a pointer, HEAD can also be moved to a different commit using the “git reset” command. By default this does not affect the working copy in any way. This is useful when you just committed two or more changes, but want to go back and commit them in a different way or in a different order.
Index
To create a new commit after files in the working copy have been locally modified, they first need to be added to the index (also a red arrow on the diagram in Fig.2). Initially the index is said to be empty. Files can be added to the index by using the “git add” command. This conceptually creates a temporary new commit, although this commit is not permanent or reachable via a hash. The commit is created as a delta between the working copy and the HEAD for the files being added.
Files in the working copy can be further modified and their delta will further be taken against the index. They can be added to the index again if needed, growing the potential new commit.
Alternatively, the “git reset” command can be used to remove files from the index. Any operation on the index creates a new temporary commit, but it does not actually create permanent commits. Remember that “git reset” is also used to move the HEAD pointer. “git reset” empties the index by default, but it also has an option to avoid affecting the index.
Commit
Finally, to create a new commit, the “git commit” command is used, which simply turns the index into a new commit. HEAD is then moved automatically to the new commit and the index is empty again. If HEAD is attached to a branch, the branch is moved to the new commit as well. This gives significance to attached or detached HEAD – for detached head no branch is moved when new commits are created. If there were any further local modifications to the working copy, which were not added to the index, these modifications are retained, because neither the “git add” nor the “git commit” operation affect the working copy in any way.
After a new change is committed, it cannot be modified or removed. There is a “git commit –amend” command, which is meant to modify the latest commit, it can add more files to a commit (via the index) or update commit message, but in practice it creates a new commit with a new hash (the amended commit has the same parent change as the original commit).
Detached HEAD
When new commits are added while HEAD is detached and then HEAD is moved to a different place, e.g. via “git checkout” or “git reset”, the commits added with detached HEAD become unreachable. They can still be reached if the user remembers their hashes or via “git reflog”, however once “git gc” is run (a.k.a. garbage collector), the unreachable commits are deleted completely.
Branches
Branches in git are simply named pointers to commits. They do not correspond to branches of the commit tree in a physical tree sense, pointers is all they are. A branch pointer can be freely moved to point to a different commit (selected via hash or other branch name) by using the “git branch” command.
In the example in Fig.2, the “develop” branch points to a leaf commit and potentially contains unstable changes, and the “master” branch points to an older commit, which is meant to be stable. Eventually the “master” branch pointer can be moved with “git branch -f” command to a newer, stable commit, or to where “develop” points to.
New branch pointers can be created with the “git branch” command and also with the “git checkout -b” command, which automatically attaches HEAD to the new branch. The new branch pointer will then be moved together with HEAD when new commits are created.
Tags
Tags in git are named commit pointers as well, just like branches and HEAD. See the blue pointer in Fig.2. Tags can also be moved, although git servers may restrict the movement of tags.
Distributed nature
Because commits are organized into a tree hierarchy, it is easy to use git repositories in a decentralized, collaborative way.
The “git clone” command creates a local copy of the repository. Typically this creates a copy of the entire repository locally, which becomes a new, local repository and references the remote repository.
The remote repository is by default called “origin” (it’s possible to have local shorthand names for remote repositories).
There can be multiple remote repositories registered and the user can pull (download) the state of selected repositories or push (upload) their changes to selected remote repositories. Both pulling and pushing can be done either for specified branches or for the entire repository.
Offline development
As mentioned above, the user typically has a copy of the whole repository locally, or of relevant branches. Therefore no network access is required to perform work on the repository. The user can commit multiple changes locally and sync the working copy to other commits or branches at will without performing any network access. Network access is only required to pull or push changes, i.e. to share with other users or for backup purposes.
Stash
Stash is a very useful feature which allows saving the current uncommitted modifications to the working copy using “git stash” command. This is useful e.g. when switching temporarily to a different branch or when downloading changes from a remote repository, without having to create a new dedicated commit. The work can later be resumed after restoring the saved modifications with “git stash pop”.
Summary
The key to using git effectively is understanding:
- The tree-like hierarchy of commits,
- The fact that “branches” and “tags” are simply pointers to commits,
- The purpose of HEAD and
- The fact that “branches” and HEAD can be freely moved around the tree.
The user interface of the command line git client is complicated and difficult to use due to unusual nomenclature and abundance of switches, which modify the commands in non-obvious ways. However, commands to perform concrete tasks can easily be looked up on Google. Check out this blog in the future for a git cheat sheet!
The great benefits of git are its reliability, robustness with regards to humongous repositories, multitude of tools supporting it and variety of services like GitHub.
See also: git log command variant, which makes it easier to view your current position in the tree.
Does type safety matter?
One of the distinctive features of programming languages is type safety, esp. static vs. dynamic typing. Let’s take C++ and Python as examples.
In C++ a variable type is determined at compile time and remains the same for the lifetime of a compiled program, while in Python a variable can change type at run time. Moreover, object types in Python can evolve at run time while members are added and removed. In practice, we can create a generic dynamic type in C++ which can contain anything and make variables behave like in Python, but we almost never do.
I was recently watching a C++ talk from some conference, where a distinguished professor claimed static typing in C++ to be superior to dynamic typing Python. To make his point, he said that Python requires you to write tests to make a program as robust as in C++. Now that does not make any sense, because you have to write tests regardless of whether your program is written in C++ or in Python. Static typing doesn’t give you any guarantees that your program will bug-free!
Some time ago there was a study which was comparing programming languages based on the number of defects occurring in programs written in these languages. In that study no significant difference was found between C++ and Python. I would take this study with a grain of salt, yet one thing stood out – that functional programming languages have less bugs than imperative languages, which is likely. You can argue with my analysis of the results of the study, but compare PERL, PHP, C and C++ and you will know what I meant with regards to the grain of salt. My point is, there is no proof that static typing vs. dynamic typing makes much difference on the quality of code.
Suffice to say, the type system in C++ is not very well designed. Let’s take a look at two examples.
Consider this program written in C or C++:
#include <stdio.h>
int main()
{
const unsigned one = 1;
printf("%s\n", (-1 > one) ? "true" : "false");
return 0;
}
It may surprise you that this program prints “true”, meaning that -1 is greater than 1. This is because of “very interesting” type promotion rules in C and C++, due to which a signed type is promoted to an unsigned type.
On top of this, in modern C++ it is recommended to use signed int type for most purposes. Contrast this to the ubiquitous unsigned size_t type in the C++ standard library.
A C++ compiler can help you identify problems in your program during compilation, especially if you enable the highest warnings level possible. You will often find out that you have lots of type-related problems in your C++ program. The solution is typically to scatter lots of static_casts across your code base. However, type casting becomes not only an annoying necessity, but it also hides bugs – check out the -1 > 1 comparison above to see what I mean.
You might say that if you use int for everything (arguments, variables, members) you won’t have to do any casting. Fine, but you can’t escape size_t! Using one type for everything also defies the purpose of having static type checking. You want diverse types to check arguments passed to functions at compile-time. But that leads to incompatible types and type casts – vicious circle!
Yet we still tend to fool ourselves into thinking that type safety is good and important…
What Android phone makers don’t want you to know
Explosive news: a new Android phone from a popular manufacturer is out. How long is it good for?
It is “good” for maybe two years. You are lucky if your Android device receives an upgrade to the latest version of Android after that time. However, when it comes to important security patches, you cannot count on promptly updates no matter how new your device is, in many cases. That is the track record of most top Android brands, including Google’s own Nexus devices.
Poor support for updates can only be expected for the most expensive devices. If you buy a cheap phone from your carrier, it usually comes with a one- or two-year old version of Android and you will never receive any updates. Sit tight and wait for malware to pwn your phone.
Moral of the story? Vote with your wallet, avoid Android if you can.
Please leave a comment if you find a phone manufacturer who gives you updates for 5 years.
The future of programming
In the near future, AI and robots will replace humans in most jobs. Until recently I thought programming would be one of the last jobs where humans would be replaced, but I don’t think so anymore.
AI-based static analysis
AI will soon find its way to help us in everything we do. Today, computer programming has lots of challenges, writing correct and bug-free programs is hard. However, I would not be surprised if there was already a startup developing a new AI-based static analysis tool to aid programmers.
We already have all the technology needed to create such tool for, let’s say, C++, or any other programming language for that matter. Here is how such tool could be crafted:
- The source code can be turned into an abstract syntax tree, in case of C++ libclang can be used for that with little effort.
- The AST can then be fed into a neural network. A library like cuDNN can be used to build such network.
- Github is a trove of source code, which can be used to train the network.
- The real innovation and the main challenge is annotating the source code with issues which the network should detect. Initially, this could be done using existing static and dynamic analysis tools, like Coverity, valgrind or sanitizers.
- The output from the neural network would just highlight issues in the source code.
The tool could be available from the command line and it could be integrated with IDEs.
Improvements
The static analysis tool described above could be further improved in several ways.
If fed with a single function as input, the tool would produce output only relevant to that function. When more context was given, e.g. a file or an entire program, the tool would detect more types of issues.
It would be easy to extend it to accept AST for more programming languages. Eventually, the neural network would be able to recognize problems in programs written in any programming language.
The output could be enhanced beyond just highlighting errors. The neural network could produce one or several proposed fixes for the problems found. At some point, the tool should also be able to select and apply the fixes automatically.
An even more interesting enhancement would be extensive code refactoring. This would require the tool to recognize problems with the design.
In a more advanced version of the tool, a human programmer would only be writing the outline for the program and our tool would be filling up the functions with code and fixing any issues in the design. Eventually, the “programmer” – actually the user (e.g. grandma), would describe what is needed using words, and the tool would generate the program directly in the machine code form, no intermediate code would be necessary.
In an even more futuristic setting, such tool could also work with an advanced 3D printer, and produce a design of a chip to print for the printer.
Do you think programming as a job for humans has a future?
Rvalue references in C++
This is a great article by Scott Meyers: Universal References in C++11
It explains what rvalues are in a very clean and concise way. This is the best explanation that I’ve found so far. All the other descriptions of rvalues and rvalue references are detailed, but too complicated…
The main topic of this article is that T&& in C++11 not always indicates an rvalue reference, but sometimes it indicates what he calls a universal reference, which is collapsed by the compiler to either an lvalue reference or rvalue reference, depending on T!
Worth a read, even as a refresher.
git, where am I?
git is a great piece of software, it is a marvel of engineering, it is very useful and reliable.
However there is one problem with git, which barely anybody mentions – it has a very unintuitive user interface! After years of using git I still feel like most git users – I have very little idea about what happens when I issue particular git commands.
Aside from its user interface, git works so well, that other version control systems exist only because they are easier to use. For example, bzr is trivial to master if you’ve ever used any other VCS. Mercurial is slightly more complicated, but after a few days of use you can get the gist of it. But git will surprise you even after years of use.
There are two reasons why git is so difficult to master. First, the git nomenclature is confusing. There is a sea of git commands and switches which modify the commands in subtle ways, so it is easy to get lost. For example, git checkout does not do what you would normally expect it to do, if you have experience from other VCSes. git reset is outright confusing and many users can’t distinguish it from git checkout. A branch in git is not really a branch, it is merely a pointer to some revision in the repository, you can conceptually use it as a branch, but you can also move this pointer to any existing revision in the repository.
Secondly, there is very little information about the state of the tree. It is very hard to find information how to see your location in the tree. Where is your HEAD pointing? Where is master pointing? These questions only scratch the surface.
Today, however, I came across the best git command, which makes it much easier to determine where things are:
git log --graph --oneline --decorate --date=relative --all
This command shows a graph of commits, it shows the location of HEAD, branches, etc.
One note is that this command does not show dangling commits, i.e. commits which are not reachable from any branch or tag. Dangling commits are created by moving the HEAD and adding new commits at that location, or by doing git reset –hard. Typical advice to find such commits is to use git reflog, but it is still difficult to extract useful information from it. The easiest way of finding all dangling commits is the following command:
git fsck --lost-found
Now if you want to include a single dangling commit in the graph, you can use git checkout to go to that commit and then display the graph. This makes life with git a little easier!
Indentation in Python
Python is one of the best designed programming languages. It is very easy to learn and it has very few gotchas (features which work in surprising ways).
There are so many languages younger than Python, which suffer from horrible design mistakes. For example, compared to many other scripting languages, in Python there are no undefined variables; Python does not prefer globals – you have to declare globals explicitly; when you try to read a non-existent object property in Python, you get an exception; Python does not perform type promotion, so it is easy to distinguish between values of different types; the list goes on.
Everything has pros and cons, and so does Python. One of the commonly mentioned issues with Python are indentation-based blocks. It’s a relatively minor issue and even though I’m not a fan of it myself, in my opinion some people make too much fuss about it.
A frequent argument against indentation-based blocks is that they rely on invisible characters, in particular tabs. There are three ways in which it could be solved:
- Set your editor to use 8-column tabs. 8-column tabs are the de facto standard, so if anyone complains about Python because their editor is buggy and defaults to any other tab size, it is essentially their own problem.
- Set your editor to convert tabs to spaces. Due to buggy editors being so widespread, it never makes sense to use tabs in source code, regardless of which programming language is used.
- Last but not least, the problem could be fixed in Python itself, by disallowing tab characters. This is a small oversight on the Python side.
As you can see, this trivial issue could be solved in several ways and there is no reason to complain about Python.
If you know a programming language, which is better designed than Python, please let me know!
The future of mobile devices
There are two main directions of evolution for mobile devices: sensors and form factor.
While there’s been some development in sensor technology, there’s still a lot of possibilities, so I’m looking forward to seeing a startup making advances in this direction.
Pocket mobile devices are quite popular, but the era of wearable computing is yet to come. Wrist devices seem promising. The current wave of smartwatches has not scratched the surface yet. Apple and other manufacturers completely don’t get it, so one day some company will come and create the perfect wrist computer.
Below is a breakdown of what an actually useful wrist computer could do.
Readable screen
A computer-like backlit mini-panel is a joke. It consumes a lot of energy, so it must be turned off when you’re not looking to save battery. The solution is obvious – take a look at Kindle. Current Kindle screens are slow to refresh, but they consume very little power and are readable in every lighting conditions, including bright sunlight and darkness. The optional backlight in a wrist device could be automatic and conditional on day/night as well as the “look at me” gesture (like in current smartwatches).
No charging
I am supposed to charge a smartwatch… every day? That is the biggest joke. That is not the direction this technology should be going in. Solar batteries and kinetic charging has been around for 30 years and more. It’s time these technologies are leveraged in wearable devices.
Voice commands
A touchscreen on a watch-sized computer, however useful and necessary, is really too small for most things, esp. typing. The input of such computer should be primarily based on voice recognition. Regardless of whether it can just listen-in for your commands or whether you need to press a button (and it should be ready within milliseconds), the input should be prefiltered and it should be able to tune-in to the owner’s voice, so that it is usable even in loud or public places, and does not accept commands from other people.
As for the actual speech recognition, solutions like SoundHound promise the future where you can say anything to your computer, and it will understand you.
Hardened and waterproof
When the device does not need to be charged (or can optionally be charged wirelessly) and does not have any buttons, it could potentially be made waterproof. The main challenge for making it waterproof would still be the microphone and speaker.
Connectivity and apps
You can expect these from any kind of computer these days. You need all sorts of notifications around the clock and you need the ability to call people and see them at the same time. The main challenge here lies in energy consumption.
Lots of sensors
Finally, there are lots of useful sensors that could make this kind of device a really useful companion:
- GPS, accelerometer, gyroscope, compass – nothing new here, you can expect these types of sensors in every mobile device these days. They can tell you your location on demand, figure out what you’re doing with the device (or with your hand), etc. I’m looking forward to the ability of using GPS without active connection, a feature of which the mobile Google Maps app has apparently forgotten, or maybe they can’t do that due to patents (all hail the patent law!).
- Temperature, pressure and humidity – it would be useful if your watch could tell you these.
- Heart rate and blood pressure – if you are in pursuit of healthy living, you need to know these.
- Spectrometer – if you go to a restaurant, you want to know if the fish you’ve been served has been poisoned with heavy metals. Even though spectrometers are still a feat of extraterrestrial rovers, someday they will revolutionize the way we do shopping and help us avoid unhealthy substances served to us by the food industry.
So would you wait for a wrist computer which is useful and not tedious, or can the coolness of the Apple Watch or an Apple Watch-like smartwatches lure you?
Can floating point representation be improved?
If you ever wrote any code which used floating point numbers, you are probably aware, that the widespread floating point format, also known as IEEE-754, is full of caveats.
Due to the representation used, floating point computations are usually unstable. The errors of certain operations grow rapidly, operations are order-dependent and you can obtain different results on different architectures.
Here is an incredibly promising proposal of unum, a number format which improves the current floating point format in all areas: John Gustafson Explains Energy Efficient Unum Computing.
There are many areas, where this could provide improvements, not only in the quality of programs, but also in energy efficiency.
In particular, scripting languages would benefit from it a lot. For example, JavaScript has a single Number type. This creates a lot of problems, because it is hard to make computations reliable, and there is a limited precision for integers. Using floating point representation for integers was a very bad design choice for JavaScript. With unum, this could change and a single numeric format would make sense.
Another example are statically typed languages, where an elaborate type system leads to headaches. With unum, this would no longer be a problem, and the type system could be simplified, especially because unums can be represented with a variable number of bits (although do not have to). Integer calculations can be carried as fast with unum as they can be carried out in regular 2’s complement representation. And at the same time, unums support floating point numbers.
Will unum prove to be useful and become widespread? I certainly hope so.
C++ wrapper for WinAPI
By popular request, I just uploaded the full WinAPI Wrapper library source code on GitHub.
This library is a very thin C++ wrapper for the Win32 API, which is a C API. The overhead of the wrapper is almost none.
The last modifications to this source originate from 2003. The development seized around that timeframe. I haven’t done any development on/for Windows for many years now, I rarely fire up Windows these days. The library can still be used for writing a wide range of apps, although I imagine that the Win32 API has evolved since and the library could benefit from some adjustments.
Whether I will maintain it further remains to be seen. 🙂
